
全国咨询热线
全国咨询热线

最近一两年接触 GP-ORCA 比较多,本文也更多是关于 ORCA 整体的一些思考和反思。
《Orca: A Modular Query Optimizer Architecture for Big Data》这篇论文主要介绍了 Greenplum 上分布式优化器的设计与实现,Orca从设计上有以下几个重点:
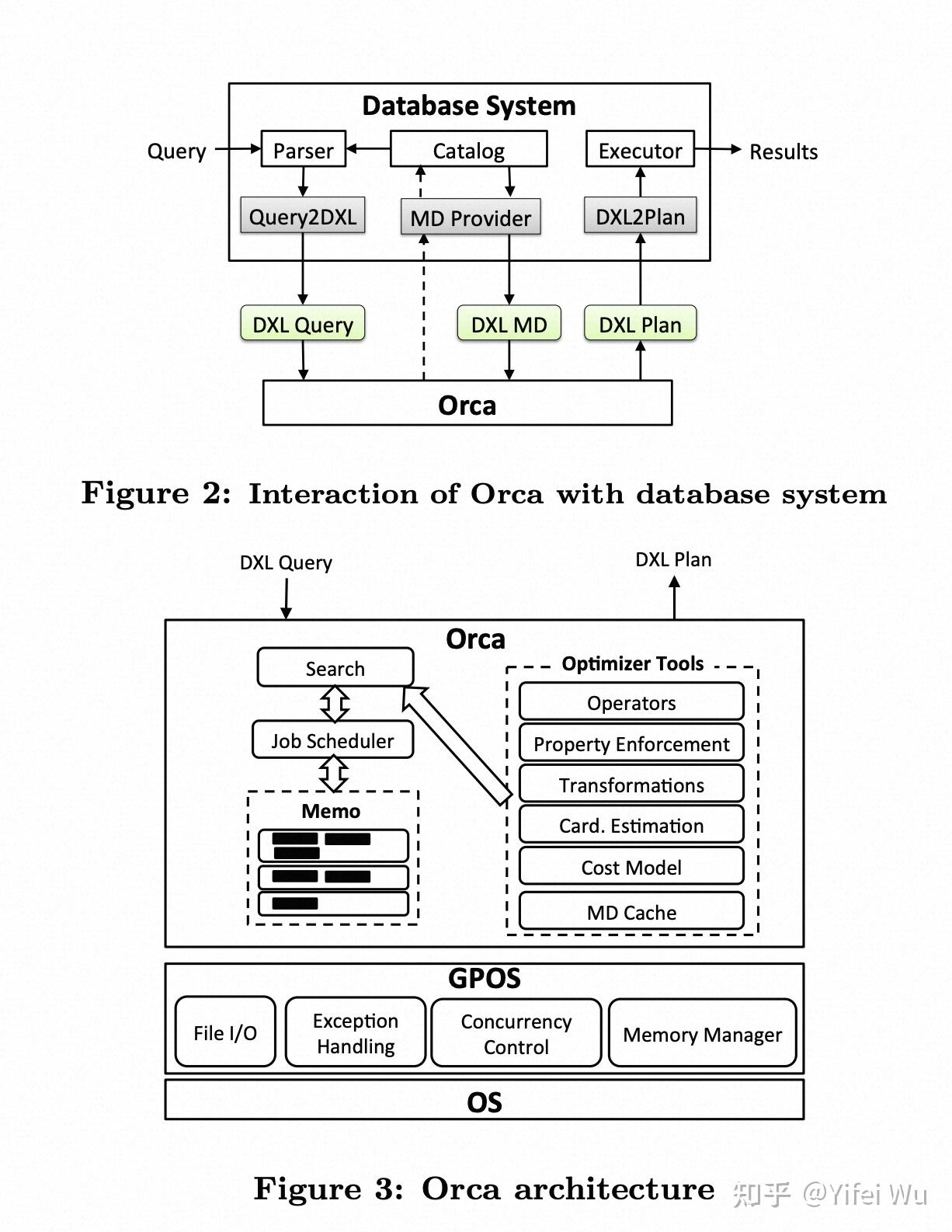
按照设计,优化器通过DXL(XML格式)来和其他模块做交互和对接,其他系统接入只需要实现对应的DXL接口,就可以使用优化器来实现一个自己的优化器。简单来说,它的算法如下:
INPUT:
1. SQL对应的原始 plan-tree,需要翻译成 DXL
2. 其他模块或者外部系统实现 IMDProvider 来提供优化器所需的 metadata 信息,包括表的属性,统计信息等。
OUTPUT:优化后的物理 plan 对应的 XML 表示格式
但是从个人经验来看,这种设计会带来比较多的额外性能开销和维护成本,主要有两点:
最后,我个人感觉优化器要做的特别通用,对大多数数仓产品来说,需求其实不是特别强烈。如果想要把优化器实现的足够靠谱,必须强依赖自身系统的特性来做优化和选择,所以其他模块有多少创新,就会有很多细节调整。市面上很多产品真正需要的只是一个简单的 SQL 语法支持,并不真正需要一个完整靠谱的优化器模块。
从开源的优化器框架来比较,Orca 在这方面确实算是很完备的工程实现。物理属性Enforce,统计信息使用推导以及完整的 Cascades 框架实现都做的比较完备。从这个角度看,Orca是一个很好的优化器参考实现。但是这来也有几点是值得说明下:
总之在分布式计划和 Cascades 框架方面, ORCA 是很具备参考性的,整体框架代码实现也比较干净。
多线程更多是一个 Demo 验证,工程实现远达不到企业级软件标准,难点在于依赖控制,这里还是很复杂的。不过目前看过开源的闭源的各种优化器,都还没怎么在多线程上有实际效果的,理论上一般也没这个性能需求。
GPOS 里能看出来 ORCA 是个早期C代码实现的项目再慢慢演进过来的。比如里面手动引用计数做内存管理,确实给工程实现带来不少的难点,哭。特别是在引用链路比较深,一些基础的类最终被发现内存泄漏或者提前释放野指针的时候,整个排查过程真的是让人头秃。这里要是能用上智能指针应该就好很多了,期待一下。
星云-星云娱乐新能源材料回收公司

微信二维码
微信号:weixin888Copyright © 2012-2018 星云-星云娱乐新能源材料回收公司 版权所有 非商用版本 琼ICP备45612387号

